|
EViews通常称为计量经济学软件包。计量经济学研究的核心是设计模型、收集资料、估计模型、检验模型、应用模型(结构分析、经济预测、政策评价)。EViews是完成上述任务比较得力的必不可少的工具。正是由于EViews等计量经济学软件包的出现,使计量经济学取得了长足的进步,发展成为一门较为实用与严谨的经济学科。强而有力和灵活性加上一个便于使用者操作的界面;新鲜的建模工具,快速直觉且容易使用的软件。EViews预测分析计量软件在科学数据分析与评价、金融分析、经济预测、销售预测和成本分析等领域应用非常广泛。 |
|
| 栏目导航 navigation |
|
|
|
|
|
|
| 您现在的位置:上海玖数软件有限公司 > EViews产品介绍 > EViews简介 |
| 上海玖数软件有限公司 作者:网站管理员 来源: 文字大小:[大][中][小] |
基本数据处理
- 数值,字母数字(字符串)和日期序列;值标签
- 广泛的运算符和统计,数学,日期和字符串函数库
- 用于表达式处理和使用运算符和函数转换数据的强大的语言
- 数据子集的样本和样本对象的方便处理
- 支持复杂数据结构,包括规则日期数据,不规则日期数据,带有观测标识符的横截面(cross-section )数据,有日期和无日期的面板数据(panel data)
- 多页面(multi-page)工作文件(workfiles)
- EViews本地,基于磁盘的数据库提供了强大的查询特征和集成EViews工作文件(workfiles)
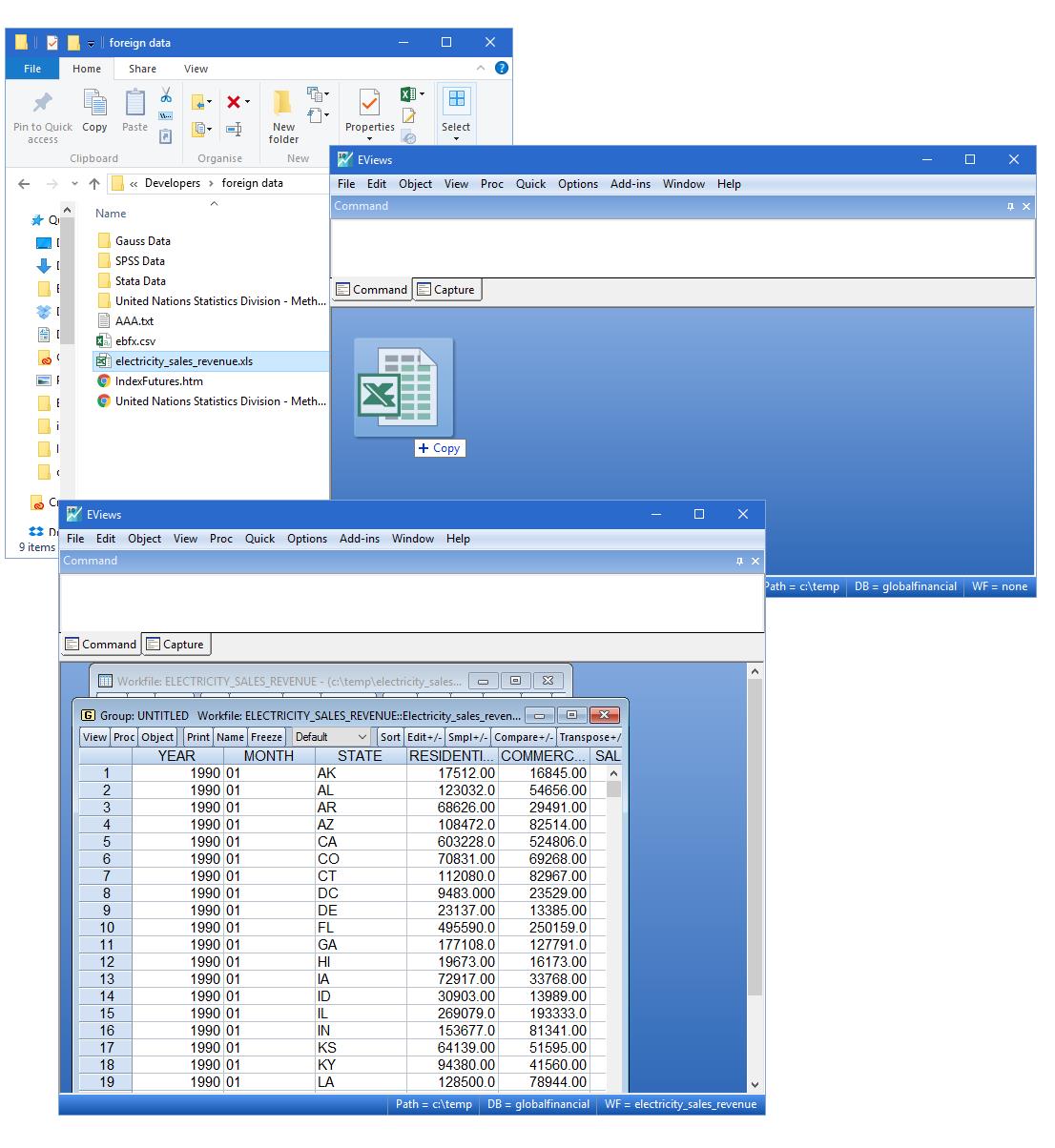
- 在EViews和各种电子表格,统计和数据库格式之间转换数据,包括(但不限于):Microsoft Access文件, Excel文件, Gauss数据集文件, ODBC Dsn文件, ODBC查询文件, SAS传输文件, 本地SPSS文件, SPSS兼容文件, Stata文件, Rats文件, GiveWin文件, TSP兼容文件, 原始格式的ASCII文本或二元文件, HTML.(注意: 只有企业版才提供ODBC支持).
- OLE支持链接EViews输出,包括表格和图形,到其它程序包,包括Microsoft Excel®, Word® and Powerpoint®.
- 支持OLEDB,用于通过OLEDB-aware客户端和自定义程序读取EViews工作文件和数据库
- 支持FRED®(Federal Reserve Economic Data)数据库。企业版支持Global Insight DRIPro 和 DRIBase, Haver Analytics® DLX®, FAME, EcoWin, Bloomberg, EIA, CEIC, Datastream, FactSet, 和 Moody’s Economy.com数据库。
- Excel插件(Add-in)允许您在Excel内链接或导入EViews工作文件或数据库数据
- 拖拉式读取数据支持:简单的拖动文件到EViews中,以自动转换外部数据到EViews工作文件格式
- 用于从已有序列中的值和数据来创建新的工作文件页面的强大工具
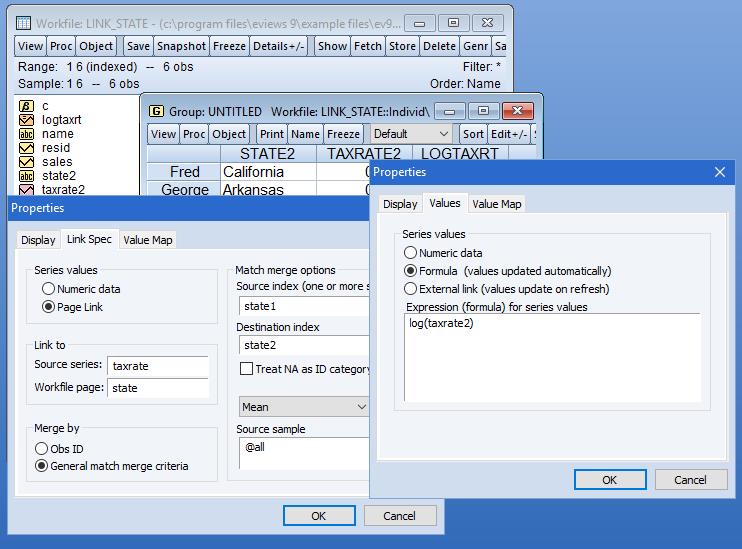
- 匹配合并,连接,追加,子集,缩放,排序和改变(堆叠和取消堆叠)工作文件
- 方便使用的自动频率转换,在页面和不同的频率之间复制或链接数据
- 当相应的数据改变时,频率转换和匹配合并支持动态更新
- 当相应的数据改变时,自动更新公式序列将会自动重新计算
- 方便使用的频率转换,在页面和不同的频率之间简单复制或链接数据。
- 用于仿真的重新抽样和随机数生成的工具。使用3种不同随机数生成器的18个不同分布函数的随机数生成。
- 支持云盘访问,允许您直接从Dropbox, OneDrive, Google Drive 和 Box账户打开和保存文件。
时间序列数据处理
- 集成支持处理日期和时间序列数据(规则和不规则)
- 对常用规则频率数据的支持(年度,半年,季度,月度,半月,两周,10天,一周,天-一周5天,天-一周7天)
- 支持高频率(当天)数据,支持小时,分钟和秒频率。另外,还有一些不常遇见的规则频率,包括多年,双月,两周,10天和天(一周内任意天数)
- 专业时间序列函数和运算符:滞后(lags),差分(differences),对数差分(log-differences),移动平均等
- 频率转换:各种高-低和低-高
- 指数平滑(Exponential smoothing):单,双,Holt-Winters
- 用于whitening回归的内置工具
- Hodrick-Prescott过滤
- Band-pass(过滤): Baxter-King, Christiano-Fitzgerald固定长度和完全样本不对称过滤器
- 季节性调整:X11, X12-ARIMA, Tramo/Seats,移动平均
- 在序列内填充遗漏值的插值法:线性,对数线性,Catmull-Rom Spline, Cardinal Spline
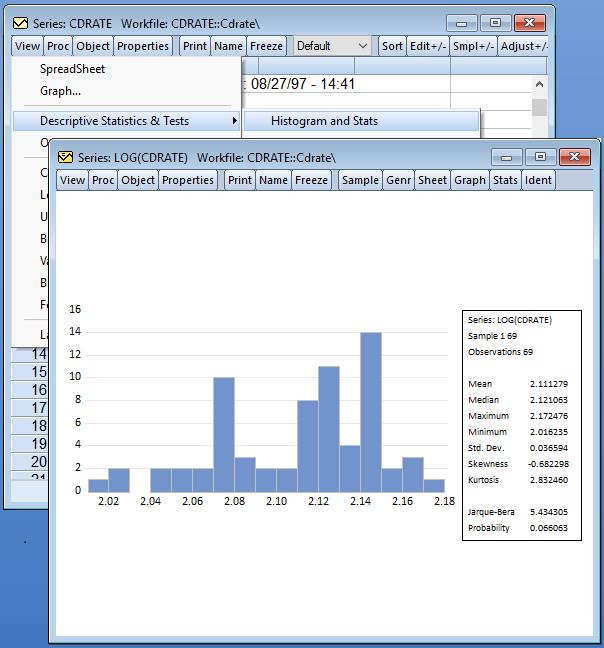
统计基本功能
- 基础数据汇总:按组汇总
- 相等性检验:t检验,方差分析(ANOVA,平衡和非平衡,有或无非齐性方差(heteroskedastic variances)),Wilcoxon, Mann-Whitney,中位数卡方,Kruskal-Wallis, van der Waerden,F检验,Siegel-Tukey, Bartlett, Levene, Brown-Forsythe
- 单向表格:带有相关测量(Phi系数, Cramer’s V, Contingency Coefficient)的交叉表和独立性检验(Pearson卡方,似然率G^2)
- 协方差和相关性分析,包括Pearson, Spearman秩排序, Kendall’s tau-a 和tau-b和局部分析(partial analysis)
- 首要成分分析(Principal components analysis)包括scree图,双标图(biplots)和载荷图(loading plots)以及加权组分计分计算
- 因子分析,允许相关性测量计算(包括协方差和相关性),唯一性估计,因素载荷估计和因子计分,以及使用超过30种不同的正交(orthogonal )和斜(oblique)方法之一执行估计诊断和因素轮换。
- 用于正态,指数,极值,Logistic,卡方(Chi-square),Weibull或Gamma分布((Kolmogorov-Smirnov, Lilliefors, Cramer-von Mises, Anderson-Darling, Watson)的经验分布函数(Empirical Distribution Function,EDF)检验
- 直方图,频数多边形(Frequency Polygons),边缘频数多边形(Edge Frequency Polygons),平均移位直方图(Average Shifted Histograms),CDF-survivor-quantile,分位数-分位数(Quantile-Quantile),核密度(kernel density),拟合的理论分布,箱线图
- 带有参数和非参数回归线(LOWESS,局部多项式(local polynomial)),核回归(kernel regression,Nadaraya-Watson, 局部线性, 局部多项式),或置信椭圆(confidence ellipses)的散点图
时间序列
- 自相关,部分自相关,互相关(cross-correlation),Q统计量
- Granger因果检验(Granger causality tests),包括面板Granger因果
- 单位根检验(Unit root tests):Augmented Dickey-Fuller,GLS transformed Dickey-Fuller, Phillips-Perron, KPSS, Eliot-Richardson-Stock Point Optimal, Ng-Perron,以及用于带有断点的单位根的检验。
- 协整检验(Cointegration tests):Johansen, Engle-Granger, Phillips-Ouliaris, Park added variables,和Hansen 稳定性。
- 独立性检验:Brock, Dechert, Scheinkman 和 LeBaron
- 方差比检验(Variance ratio tests): Lo and MacKinlay, Kim wild bootstrap,Wright's rank, rank-score和sign检验。Wald和多重比较方差比检验(Richardson and Smith, Chow and Denning).
- 长期方差(Long-run variance)和协方差计算:使用非参数内核(Newey-West 1987, Andrews 1991), 参数VARHAC (Den Haan and Levin 1997)和prewhitened内核(Newey-West 1987, Andrews 1991), 参数VARHAC (Den Haan and Levin 1997)和prewhitened内核 (Andrews and Monahan 1992)方法的对称或单侧长期协方差。另外,EViews支持Andrews (1991)和Newey-West (1994)的用于内核估计器的自动带宽选择方法(automatic bandwidth selection methods),以及用于VARHAC和prewhitening估计的基于滞后长度选择方法的信息准则。
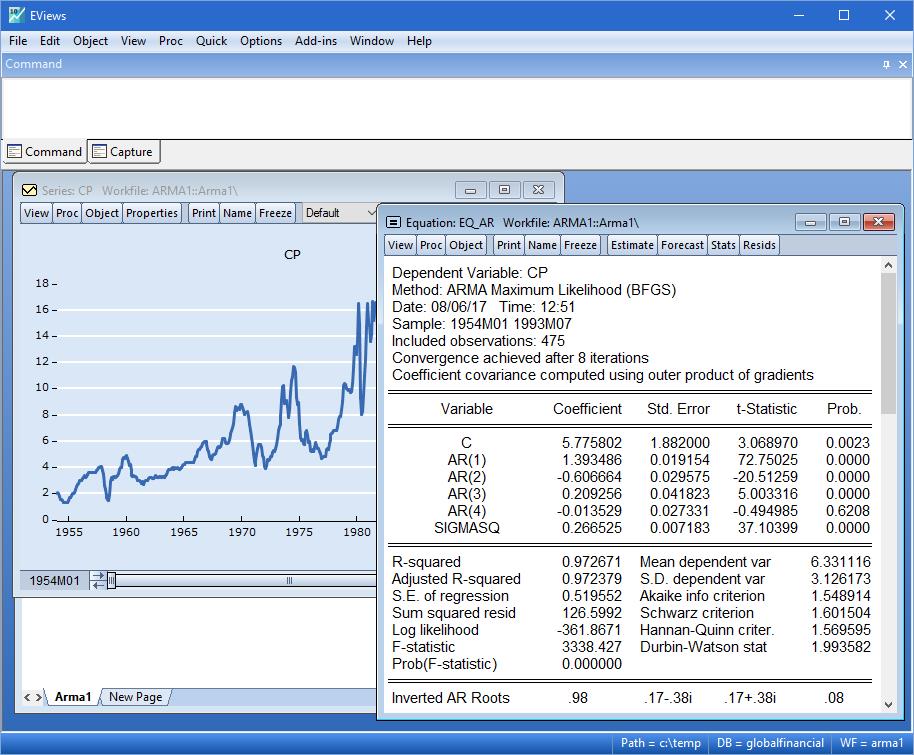
ARMA 和 ARMAX
- 带有自回归移动极差,季节性自回归和季节性移动极差误差的线性模型。
- 带有AR和SAR规格的非线性模型
- 使用Box和Jenkins的向后预测法(backcasting method)或条件最小二乘法,ML或GLS的估计
- Fractionally integrated ARFIMA models
工具变量和GMM
- 线性和非线性2阶段最小二乘法/工具变量(2SLS/IV)和广义矩估计方法(Generalized Method of Moments (GMM) estimation)
- 带有AR和SAR误的线性和非线性2SLS/IV估计
- 有限信息最大似然(Limited Information Maximum Likelihood (LIML))和K类估计
- 由加权矩阵迭代控制的宽泛的GMM加权矩阵规格(White, HAC,用户提供的)。
- GMM估计选项,包括持续更新估计(continuously updating estimation (CUE)),和许多新的标准误选项,包括Windmeijer标准误
- IV/GMM特定诊断,包括工具正交检验(Instrument Orthogonality Test),回归量外生检验(Regressor Endogeneity Test),Weak工具检验(Weak Instrument Test)和GMM特定断点检验
ARCH/GARCH
- GARCH(p,q), EGARCH, TARCH, Component GARCH, Power ARCH, 集成的GARCH.
- 线性或非线性均值方程可以包括ARCH和ARMA条款:所有的均值和方差方程允许外生变量(exogenous variables)
- 正态,学生t和广义误差分布(Generalized Error Distributions)
- Bollerslev-Wooldridge稳健标准误
- 条件方差(conditional variance)和均值以及永久成分(permanent components)的样本内和样本外预测
受限因变量模型
- 二元Logit,Probit和Gompit(极值)
- 次序Logit,Probit和Gompit(极值)
- 带有正态,logistic和极值误差(Tobit等)的删失(censored)和截断(truncated)模型
- 带有泊松,负二项和准极大似然(quasi-maximum likelihood (QML))规格的计数模型
- Heckman选择模型
- Huber/White稳健标准误
- 计数模型支持广义线性模型或QML标准误
- 用于二元模型的Hosmer-Lemeshow和Andrews拟合优度检验
- 方便保存结果(包括广义残差和渐变)到新的EViews对象以用于进一步的分析
- General GLM estimation engine may be used to estimate several of these models, with the option to include robust covariances.
面板数据/合并时间序列,横截面数据
- 带有附加横截面(additive cross-section)和周期固定或随机效应的线性和非线性估计
- 用于在随机效应模型:Swamy-Arora, Wallace-Hussain, Wansbeek-Kapteyn中的成分方差(component variances)的二次无偏估计量(quadratic unbiased estimators (QUEs))的选择
- 带有横截面和周期固定或随机效应的2SLS/IV估计
- 在一个转换的规格上使用非线性最小二乘法进行带有AR误差的估计
- 广义最小二乘法,广义2SLS/IV估计,GMM估计允许横截面或周期异方差(heteroskedastic)和相关规格
- 使用带有周期指定的预定义工具(Arellano-Bond)的一阶差分(first differences)或正交偏差(orthogonal deviations)的线性动态面板数据估计
- Panel serial correlation tests (Arellano-Bond).
- 包括7种稳健White和面板修正(Panel-corrected)标准误(PCSE)的稳健标准误的计算
- 系数限制,遗漏和冗余变量的检验,用于相关随机效应的Hausman检验
- 面板单位根检验:Levin-Lin-Chu, Breitung, Im-Pesaran-Shin, 使用ADF和PP检验(Maddala-Wu, Choi)的Fisher-type检验, Hadri.
- Panel cointegration estimation: Fully Modified OLS (FMOLS, Pedroni 2000) or Dynamic Ordinary Least Squares (DOLS, Kao and Chaing 2000, Mark and Sul 2003).
- Pooled Mean Group (PMG) estimation.
广义线性模型GLMs
- 正态,泊松,二项,负二项,伽马,逆高斯,指数均值,幂均值(Power Mean),二项平方簇
- 识别, log, log-complement, logit, probit, log-log, complimentary log-log, 逆,幂(power), 幂比值比(power odds ratio), Box-Cox, Box-Cox比值比(odds ratio)链接函数
- 先验方差(Prior variance)和频率加权
- 固定,Pearson卡方,偏差(deviance)和用户指定的离差(dispersion)规格.支持QML估计和检验
- 二次爬坡(Quadratic Hill Climbing), Newton-Raphson, IRLS - Fisher计分(scoring)和BHHH估计算法
- 使用预期或观测的Hessian或渐变(gradients)的矢量积(outer product)进行普通系数协方差(Ordinary coefficient covariances)的计算。使用GLM或Huber/White方法进行Robust协方差估计。
多变量ARCH
- 条件常量相关(Conditional Constant Correlation)(p,q),诊断VECH(p,q), 诊断BEKK (p,q), 带有不对称条件
- 用于诊断VECH的系数矩阵的广泛的参数化选择
- 均值和方差方程式允许外生变量(Exogenous variables);均值方程式中允许非线性和AR条件
- Bollerslev-Wooldridge稳健标准误
- 正态和学生t多变量误差分布
- 分析或(快或慢)数值衍生的选择。(在一些复杂模型中分析衍生不可用)
- 从估计的ARCH模型在各种表格和图形格式中生成协方差,方差或相关
检验和估计
- 实际的,拟合的,残差图
- 用于非线性系数限制的Wald检验;置信椭圆(confidence ellipses)显示估计参数的任意两个函数的联合置信区域
- 其他系数诊断:标准化系数和弹性系数(coefficient elasticities),置信区间,方差膨胀因子(variance inflation factors),系数方差分解
- 遗漏和冗余变量LR检验,残差和平方残差相关图和Q统计量,残差序列相关和ARCH LM检验
- White, Breusch-Pagan, Godfrey, Harvey和Glejser异方差检验
- 稳定性诊断:Chow拐点和预测检验,Quandt-Andrews未知拐点检验,Ramsey RESET检验,OLS递归估计,影响统计量(influence statistics),杠杆图(leverage plots)
- ARMA方程诊断:逆根AR和/或MA特征多项式的图形和表格,比较结构化残差的理论(估计)自相关模式和实际相关模式,显示ARMA脉冲响应到创新冲击(shock)和ARMA频谱。
- 方便保存结果(系数,系数协方差矩阵,残差,梯度(gradients)等)到EViews对象,以方便进一步的分析。
预测和仿真
- 从带有预测标准误计算的估计得方程对象得到的样本内或样本外静止或动态预测
- 预测图形和样本内预测评估:RMSE, MAE, MAPE,Theil不等式系数和比例
- 用于多方程式预测和多变量仿真的先进的模型构建工具
- 模型方程可以以文本或作为链接的方式输入,以用于重新估计时的自动更新
- 显示您的方程的依存性结构或外生和内生变量
- 用于非随机和随机仿真的Gauss-Seidel, Broyden 和 Newton模型求解器。用于模型一致性预期的非随机前瞻性方案求解。随机性仿真可以使用自举(bootstrapped)残差。
- 求解控制问题,以便内生变量达到用户指定的目标
- 复杂方程标准化,增加因子和重写支持
- 管理和比较涉及各种假设设置的多个方案情景
- 以图形和表格形式构建模型视图和过程显示仿真结果。
图形和表格
- 线条,点图,区域,条形,spike,季节性,饼图,xy线条,散点图,箱线图,误差条,high-low-open-close和区域带
- 强大,容易使用的分类和汇总图形
- 自动更新图形,随对应的数据更改而更新
- 当您移动鼠标指针到图形上的某个点时,显示观测值信息和具体值
- 直方图,平均偏移直方图,频率多边形,边缘频率多边形,箱线图,核密度,拟
理论分布,CDF,幸存,分位数,分位数-分位数
- 散点图,带有任意组合参数和非参数核(Nadaraya-Watson,局部线性,局部非线性)和近邻(LOWESS)回归线或置信椭圆
- 交互式点击或给予命令的自定义
- 图形背景,框架,图例,坐标轴,尺度,符号,文本,阴影,渐变的大量的自定义,带有改善的图形模版特征
- 表格自定义,控制单元格字体,大小和颜色,单元格背景颜色和边框,合并和注释
- 复制和黏贴图形到其他Windows程序,或保存图形为Windows常规或增强的metafiles,压缩的PostScript文件,位图,GIF,PNG或JPG格式文件
- 复制和黏贴表格到其他程序或保存为RTF,HTML或文本文件
- 管理图形和表格一起到一个spool对象,让您在一个对象中显示多个结果和分析
命令和编程
- 面对对象的命令语言,提供访问菜单项目
- 在程序文件中的批处理执行命令
- 循环和条件分支,子程序和宏处理
- 用于字符串处理的字符串和字符串矢量对象。字符串和字符串列表函数的详尽的库。
- 广泛的矩阵支持:矩阵操作,相乘,逆,Kronecker积,特征值解法和奇异值分解。
EViews 11中的新功能
EViews 11具有广泛的令人兴奋的变化和改进。以下是版本11中重要的新功能的概述。
EViews接口
交互式命令资源管理器,用于查看对象及其文档的所有适用命令。
名称和命令自动完成。
基于价值的电子表格和Geomap着色。
数据处理
与Python集成。
重复分析。
分裂观测高频到低频转换方法。
与以下数据源的接口
经济分析局(BEA)。
美国人口普查。
国家海洋和大气管理局。
图表,表格和线轴
地理地图。
粉丝图表。
计量经济学与统计学
估计
改进的贝叶斯VAR。
混合频率VAR。
切换VAR(马尔可夫和简单)。
弹性网和LASSO机器学习。
功能系数和局部回归。
其他集群强大的标准错误。
测试和诊断
季节性单位根测试。
|
|
|


